Several journals now request data and/or code to be made openly available in a permanent repository accessible via a digital object identifier (doi), which is – in my opinion – generally a really good thing. However, there are associated challenges. First, because the expectation that code and data are made openly available is quite new (still nowhere near ubiquitous), many authors do not know of an appropriate workflow for managing and publishing their code. If code and data has been developed on a local machine, there is work involved in making sure the same code works when transferred to another computer where paths, dependencies and software setup may differ, and providing documentation. Neglecting this is usually no barrier to publication, so there has traditionally been little incentive to put time and effort into it. Many have mad great efforts to provide code to others via ftp sites, personal webpages or over email by request. However, this relies on those researchers maintaining their sites and responding to requests.
I thought I would share some of my experiences with curating and publishing research code using Git, because actually it is really easy and feeds back into better code development too. The ethical and pragmatic arguments in favour of adopting a proper version control system and publishing open code are clear – it enables collaborative coding, it is safer, more tractable and transparent. However, the workflow isn’t always easy to decipher to begin with. Hopefully this post will help a few people to get off the ground…
Version Control:
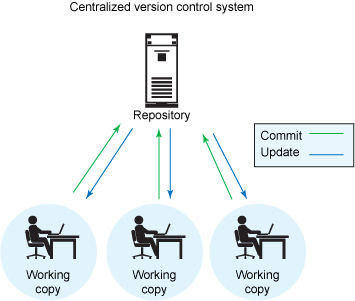
Version control is a way to manage code in active development. It is a way to avoid having hundreds of files with names like “model_code_for _TC_paper_v0134_test.py” in a folder on a computer, and a way to avoid confusion copying between machines and users. The basic idea is that the user has an online (‘remote’) repository that acts as a master where the up-to-date code is held, along with a historical log of previous versions. This remote repository is cloned on the user’s machine (‘local’ repository). The user then works on code in their local repository and the version control software (VCS) syncs the two. This can happen with many local repositories all linked to one remote repository, either to enable one user to sync across different machines or to have many users working on the same code.
Changes made to code in a local repository are called ‘modifications’. If the user is happy with the modifications, they can be ‘staged’. Staging adds a flag to the modified code, telling the VCS that the code should be considered as a new version to eventually add to the remote repository. Once the user has staged some code, the changes must be ‘committed’. Committing is saving the staged modifications safely in the local repository. Since the local repository is synced to the remote repository by the VCS, I think of making a commit as “committing to update the remote repository later”. Each time the user ‘commits’ they also submit a ‘commit message’ which details the modifications and the reasons they were made. Importantly, a commit is only a local change. Staging and committing modifications can be done offline – to actually send the changes to the remote repository the user ‘pushes’ it.
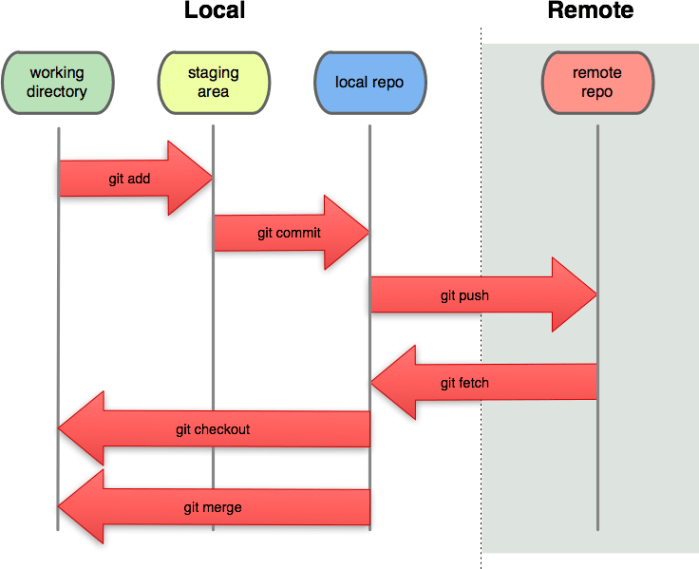
Sometimes the user might want to try out a new idea or change without endangering the main code. This can be achieved by ‘branching’ the repository. This creates a new workflow that is joined to the main ‘master’ code but kept separate so the master code is not updated by commits to the new branch. These branches can later be ‘merged’ back onto the master branch if the experiments on the branch were successful.
These simple operations keep code easy to manage and tractable. Many people can work on a piece of code, see changes made by others and, assuming the group is pushing to the remote repository regularly, be confident they are working on the latest version. New users can ‘clone’ the existing remote repository, meaning they create a local version and can then push changes up into the main code from their own machine. If a local repository is lagging behind the remote repository, local changes cannot be pushed until the user pulls the changes down from the remote repository, then pushes their new commits. This enables the VCS and the users to keep track of changes.
To make the code useable for others outside of a research group, a good README should be included in the repository, which is a clear and comprehensive explanation of the concept behind the code, the choices made in developing it and a clear description of how to use and modify it. This is also where any permissions or restrictions on usage should be communicated, and any citation or author contact information. Data accompanying the code can also be pushed to the remote repository to ensure that when someone clones it, they receive everything they need to use the code.
One great thing about Git is that almost all operations are local – if you are unable to connect to the internet you can still work with version control in Git, including making commits, and then push the changes up to the remote repository later. This is one of many reasons why Git is the most popular VCS. The name refers to the tool used to manage changes to code, whereas Github is an online hosting service for Git repositories. With Git, versions are saved as snapshots of the repository at the time of a commit. In contrast, many other VCSs log changes to files.
There are many other nuances and features that are very useful for collaborative research coding, but these basic concepts are sufficient for getting up and running. It is also worth mentioning BitBucket too – many research groups use this platform instead of GitHub because repositories can be kept private without subscribing to a payment plan, whereas Github repositories are public unless paid for.
Publishing Code
To publish code, a version of the entire repository should be made immutable and separate from the active repository, so that readers and reviewers can always see the precise code that was used to support a particular paper. This is achieved by minting a doi (digital object identifier) for a repository that exists in GitHub. This requires exporting to a service such as Zenodo.
Zenodo will make a copy of the repository and mint a doi for it. This doi can then be provided to a journal and will always link to that snapshot of the repository. This means the users can continue to push changes and branch the original repository, safe in the knowledge the published version is safe and available. This is a great way to make research code transparent and permanent, and it means other users can access and use it, and the authors can forget about managing files for old papers on their machines and hard drives and providing their code and data over email ‘by request’. It also means the authors are not responsible for maintaining a repository indefinitely post-publication, as all the relevant code is safely stored at the doi, even if the repository is closed down.
